It was a bit miserable last Friday morning; the kind of day when you don’t want to get out of bed. Not only did I get up, I got up early, as bringing me from Brighton, downcast under slate-grey skies, to London, land of steel and glass, and in particular the dull purple glow of the trendy The Brewery’s rave-lit interior, was Extract, a conference by web data company import.io, billed as “data stories worth sharing”.
Dessert-themed text under purple event lighting
First impressions of The Brewery
The Brewery was a classier venue than I’m used to for this sort of thing, with break-time snacks that were so fancy they went straight to being interesting without being particularly concerned about being nice (witness the passionfruit, raspberry and basil marshmallow lollipops). Their toilet signs (below) also made me feel like I'd fallen into hipster hell. The lunch (I had the beef) was delicious, though, and everything was agreeably well-presented.
Bathroom directional sign with male and female icons on pink background
Keynote by David Spiegelhalter
After some milling-around and croissant-eating, we all moved into the main hall and David White, import.io founder and CEO did the introduction (but I must confess I was too distracted by his resemblance to Gavin Belson, the evil Hooli CEO from HBO’s Silicon Valley to listen to much of what he was saying (for real, look at this)). This lead into the keynote talk was from the (very enthusiastic) Cambridge academic and celebrity statistician David Spiegelhalter, and was, in the nicest way possible, a pitch for his book. That said, it was a very good pitch, and I do now want to go and read his book. He made laudable attempts to make it relevant to the audience, and was fun, interesting, engaging. Apologies to my statistics lecturers: I wish he’d been my statistics lecturer.
David Spiegelhalter presenting 'Sex by Numbers' book on stage at a conference
Talks that stood out
The rest of the talks were, regrettably, a bit of a mixed bag – some suffered from technical issues, some a paucity of interesting content and some an overabundance of it (one in particular went on over twice as long as scheduled).
Spotify, Microsoft, and Lyst highlights
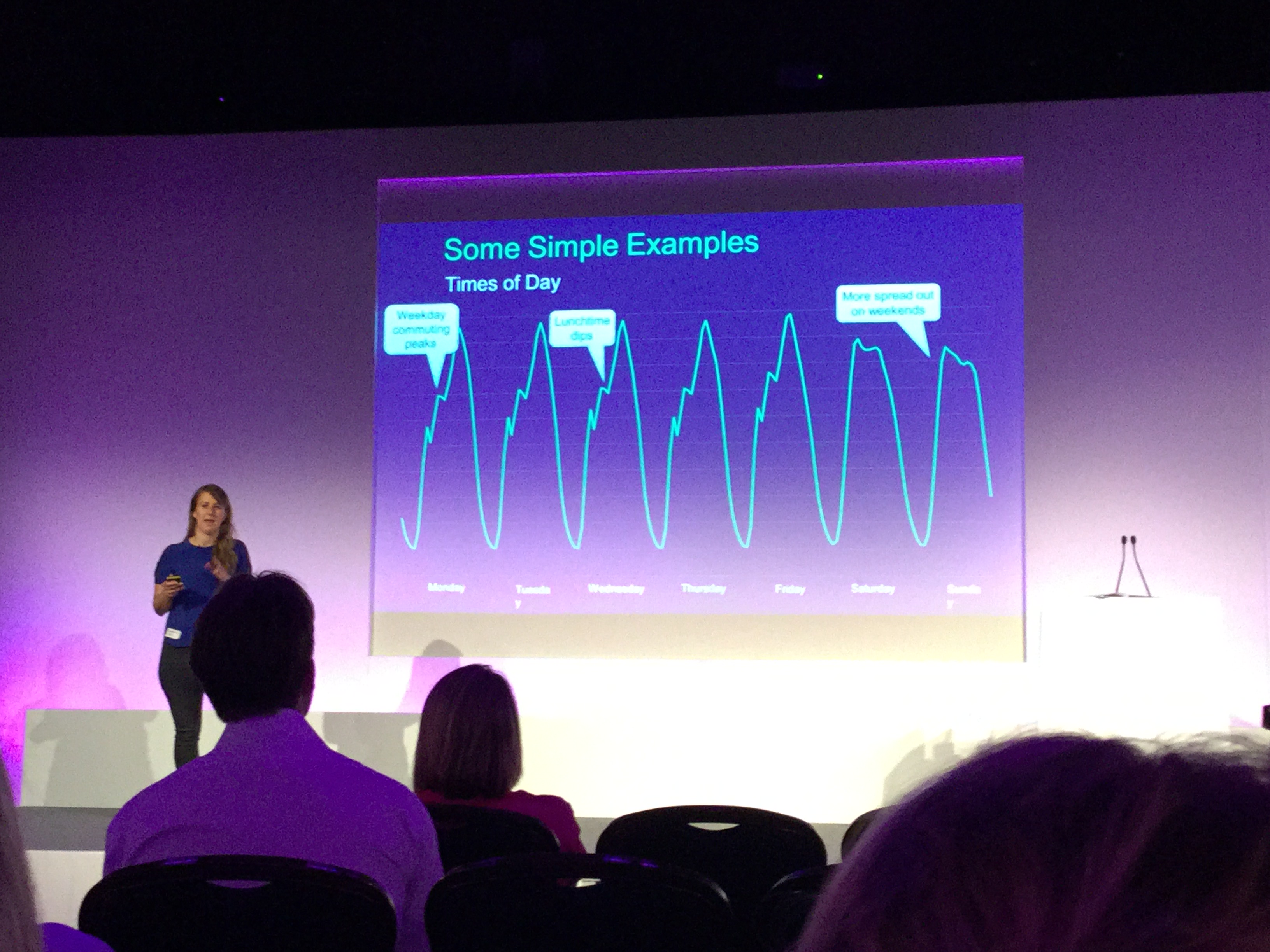
There were, however, a few highlights which stood out for me. Samantha Mandel-Dallal from Spotify showed some really fascinating data about when people listen to their music, from what source – playlist, artist page, etc. Microsoft evangelist Andrew Fryer had to rush his talk a little but delivered what I found an interesting consideration of the ethical treatment of data, something that doesn’t get talked about often enough. Eddie Bell of Lyst, who had lots of good chat about colour recognition and colour spaces and the challenges of auto-listing clothes when the colours had incredibly abstruse names and auto-recognition was very difficult.
Speaker presenting a time-of-day data visualisation chart showing traffic patterns at a conference
Reflections on the day
These were the best talks of the day, the stories that really made me think about how we could (and should) be using our data, and likewise how we should be advising out clients, but in the end they were just too few and far between. The rest of the time, I applaud the team for playing the hand they were dealt as best they could, struggling valiantly with technical issues and illness, as these marred an otherwise promising set of speakers' presentations. Sadly, parts of the day were somewhat of a slog, but I'm sure this will be remedied in future, and I look forward to the next event all the same.
Speaker presenting about spacetime with aerial map imagery at a conference
Ready to talk?
Book a free discovery call to discuss how we can help with your data and analytics challenges.






{kind=link}