Ask your data a question: the promise (and reality) of natural language to SQL
Matthew Hooson•28 November 2025•13 min read
Unless you've spent the last year in a particularly deep cave, you've probably heard the phrase "just ask your data a question" thrown around with wild abandon. The dream is seductive: instead of bothering your already overwhelmed data team with yet another ad hoc query, you simply type "How many users spent more than 20 minutes on site yesterday?" and watch the magic happen. SQL appears, results flow, insights materialise.
I'll be honest, I've been one of the people promising this future. But having spent considerable time poking, prodding, and occasionally pleading with these tools, I think it's time for a more nuanced conversation about where we actually are. Because here's the thing: Natural Language to SQL is genuinely impressive. It's also genuinely limited. And understanding the gap between those two truths is crucial if you want to get real value from these technologies.
What are we actually talking about?
At its core, Natural Language to SQL (NL-SQL) does exactly what it says on the tin. You write a question in normal human language, and an AI model translates that into SQL that queries your specific data set/project/table. In the BigQuery world, this means turning on the Gemini API, clicking "generate SQL with Gemini," and watching your question transform into a fully working query within seconds.
This isn't some distant future technology, it's available right now in BigQuery. And it works. Sort of.
March 2026 update
Since our webinar in December 2025, Google has introduced Data Agents in BigQuery - a formalised way to define data context, instructions, and knowledge sources for NL-SQL. Crucially, Data Agents now support custom glossary terms (Preview) and can import business glossary terms from Dataplex Universal Catalog (GA since June 2025), giving the model structured business context rather than relying on schema names alone. BigQuery has also launched Data Canvas, a visual workspace where you can explore, query, and visualise data using natural language prompts powered by Gemini.
The metadata problem
Here's where things get interesting. We recently ran a webinar where we put these tools through their paces using the Google Analytics 4 data for the Google Store. For those who've worked with GA4 data in BigQuery, you'll understand the pain, the event-based schema with its nested parameters is one of the most challenging structures to query correctly.
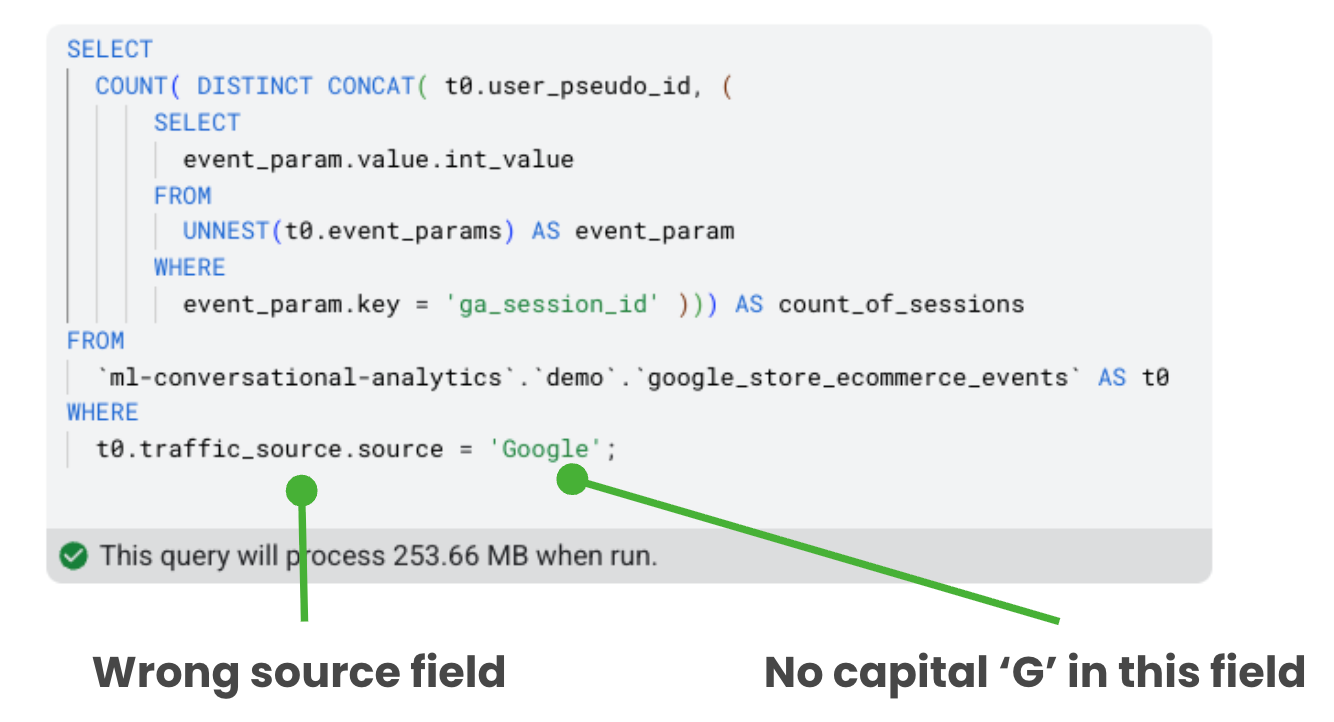
We asked a simple question: "How many sessions came from Google?"
The NL-SQL produced a query that, on first inspection, looked perfect. It counted distinct combinations of user pseudo ID and session ID, filtered by source. Textbook stuff. But look closer and you'll spot two problems. First, it used traffic_source.source instead of the session-scoped source from event parameters or the newer session_traffic_source_last_click.manual_campaign.source field, a subtle but important distinction in attribution. Second, it filtered for "Google" with a capital G, while the actual data uses lowercase.
March 2026 update
Since December 2025, BigQuery Data Agents have added support for verified queries (previously called "golden queries") — pre-validated SQL that the agent references when it encounters specific question types. For a case like ours, you could create a verified query that correctly handles session-scoped attribution via session_traffic_source_last_click, and the agent would use that as a template rather than guessing. This doesn't eliminate the need for human validation, but it gives you a mechanism to lock in correct logic for your most common questions.
This isn't a failure of the AI. It's a failure of context.
The model doesn't know your data. It doesn't know that your organisation uses lowercase values, or that session attribution lives in a different place than first-user attribution. It's making educated guesses based on schema names and general knowledge of analytics concepts. Sometimes those guesses are right. Often, they're plausibly wrong, which is arguably worse than being obviously wrong.
The semantic layer is everything
In our second example, we simply asked NL2SQL to show how many bots were on site. The immediate output was nonsensical - the SQL generated counts the number of unique user_pseudo_ids where user_pseudo_ids is NULL…
The problem here is that this information is held under event_params - a nested column that NL2SQL cannot read information about just from looking at column names.
So how do you fix this? Metadata. Lots of it.
When we added table and column descriptions explaining that bot detection flags could be found in event parameters, the model correctly started pulling from the right place. When we pre-unnested the data with clearly named columns like session_source, the attribution problem disappeared.
This is the uncomfortable truth about conversational analytics: the more effort you put into describing your data, the better results you get out. There's no magic shortcut. If you want these tools to understand that "conversions" means your specific purchase event, or that "engaged users" follows your particular definition, you need to tell them. Explicitly. Repeatedly.
Think of it like onboarding a new analyst. You wouldn't expect them to intuitively understand your attribution model, your naming conventions, or your business-specific metrics on day one. The AI is no different, except it forgets everything between prompts unless you've baked that knowledge into the system instructions.
March 2026 update
Google has since formalised much of what we were doing manually here. BigQuery Data Agents now let you define custom glossary terms that map business language to specific fields and logic — so "bot traffic" can be formally defined as a term linked to the relevant event parameter. Combined with Dataplex Universal Catalog's business glossary (GA since June 2025), you can maintain a single vocabulary across your organisation that both humans and AI reference. The broader industry trend toward formal semantic layers (LookML, dbt Semantic Layer) as the grounding layer for AI-driven analytics reinforces the same principle: don't expose raw data to AI in the first place.
The tool landscape
Currently, there are several ways to access NL-SQL capabilities in the Google Cloud ecosystem, each with different trade-offs.
BigQuery's built-in Gemini integration is the most accessible starting point. It's quick, free (beyond standard Gemini token costs), and genuinely useful for analysts who have enough SQL knowledge to critique and refine the output. This is the key point: it's a productivity accelerator for people who already understand SQL, not a replacement for SQL knowledge.
Looker Studio Pro's Conversational Analytics promises a more user-friendly interface. You create agents, connect them to data sources, and let stakeholders ask questions directly. In theory, this is exactly what data teams have been crying out for, a way to handle ad hoc questions without becoming a permanent bottleneck.
In practice? It's frustratingly inconsistent. We had an agent working perfectly one day, returning session-attributed traffic correctly. The next day, same agent, same question, different answer, it was arguing with us about whether it was doing session-level attribution (it wasn't). By day 3 everything fell apart, it refused to talk to us entirely, complaining about access which was unchanged. Add to all of this a level of obscurity between questions asked and BQ costs, which could get away from you if not properly managed. The technology will get there, the potential is obvious, but right now it's not something I'd put in front of stakeholders expecting reliable, trustworthy results.
The Conversational Analytics API and Agent Development Kit (ADK) represent the more powerful end of the spectrum. These let you build custom applications with multiple data sources, sophisticated prompting, and the ability to embed conversational interfaces wherever your users already work, Slack, Looker Studio dashboards, and internal tools.
The trade-off is complexity. You're now in the territory of Python development, cloud infrastructure, and understanding concepts like MCP toolboxes. But you also get far more control over the "semantic layer", those crucial descriptions, glossaries, and relationship mappings that make the difference between useful and useless responses.
Need help with your data platform?
We build intelligence platforms on BigQuery, Dataform and Google Cloud — from setup to ongoing optimisation.
The tool landscape has shifted meaningfully since December 2025. BigQuery now offers Data Agents with glossary terms, verified queries, and curated knowledge sources — effectively productising the "semantic layer" we were building by hand. Looker Studio Pro's Conversational Analytics has continued to mature, adding a Code Interpreter (Preview) that translates natural language into Python for more advanced analysis beyond what SQL alone can do. On the custom development side, Google has launched a fully managed BigQuery remote MCP server (Preview, auto-enabled for new projects after March 17, 2026), which lets LLM agents connect directly to BigQuery using the open Model Context Protocol. The ADK now includes a BigQuery Agent Analytics plugin for streaming agent interaction data into BigQuery for performance monitoring. The build-your-own path is becoming considerably more accessible.
The pattern that emerges
If there's one insight I'd want you to take away, it's this: there's a direct relationship between effort invested and value extracted.
NL-SQL in BigQuery is low effort but only useful for analysts. Looker Studio Pro is moderate effort but currently too buggy for production use. The API and ADK approaches require significant investment but unlock genuine democratisation of data across an organisation.
The deciding factor isn't the technology, it's the semantic layer you build around your data. The descriptions, the glossaries, the example queries, the business context. Without that investment, even the most sophisticated tools will give you plausible-sounding nonsense.
March 2026 update
Google has essentially productised these best practices through Data Agents. You restrict accessible tables by selecting specific knowledge sources. You pre-define metrics through glossary terms and verified queries. And the agent validates generated SQL before execution. The organisations getting real value aren't just following these habits informally - they're using the tooling Google has built specifically to enforce them.
What about dashboards?
A reasonable question at this point: if conversational analytics works, do we still need dashboards?
Absolutely. Dashboards remain essential for consistent, repeatable reporting, the kind of thing multiple stakeholders need to glance at and get the same answer. Conversational interfaces are brilliant for exploration, ad hoc questions, and surfacing unexpected insights. But when the CFO needs to see last month's revenue broken down by region, you want a dashboard, not a chatbot.
This isn't an either/or proposition. It's about using the right tool for the right job.
March 2026 update
Since December 2025, Looker (the enterprise platform) has made Conversational Analytics generally available, including the ability to embed it directly within Looker dashboards or into external applications via iframe. Looker Studio Pro also supports Conversational Analytics, though still in Preview. In both cases, the layered approach - governed KPIs on the dashboard, exploratory chat within safe data boundaries - is now a concrete product feature rather than just a design philosophy.
Getting started without getting lost
If you're thinking about exploring this space, here's my honest advice.
First, assess your data readiness. If your data is a mess, inconsistent naming, undocumented transformations, tribal knowledge locked in people's heads, these tools will amplify the mess, not fix it. Get your house in order first.
Second, start with a specific use case. Don't try to build a general-purpose "ask anything" solution. Identify a particular stakeholder group with a particular type of question, build for that, and learn from the experience.
Third, budget time for the semantic layer. This is where the real work happens. Every hour spent documenting your data, defining your metrics, and creating clear descriptions will pay dividends in the quality of AI-generated responses.
Finally, keep humans in the loop. Monitor what questions people are asking, what answers the system is giving, and where it's going wrong. Feed that learning back into your system instructions. This isn't a "set and forget" technology.
March 2026 update
Google's ADK now includes a BigQuery Agent Analytics plugin that streams agent interaction data - questions asked, SQL generated, execution results, costs - directly into BigQuery for analysis. This makes it significantly easier to build the kind of monitoring we'd recommend: benchmark question sets, accuracy tracking over time, cost per answered question, and hallucination logging. If you're building custom conversational analytics, this plugin removes much of the observability plumbing you'd otherwise need to build yourself.
The honest assessment
Natural Language to SQL represents genuine progress. It can meaningfully accelerate workflows for data-literate users and, with sufficient investment, can put analytical capabilities in the hands of stakeholders who'd never write SQL themselves.
But it's not magic. It requires good data, extensive metadata, and realistic expectations. The gap between the marketing promise ("just ask your data anything!") and the practical reality ("carefully instruct the AI about your specific context and verify its answers") is substantial.
That gap will close over time. The technology is improving rapidly, and each generation of models gets better at understanding context and nuance. But right now, in early 2025, the organisations getting value from these tools are the ones approaching them with eyes open, investing in the unsexy work of data documentation while keeping humans firmly in the loop.
If you want to explore how conversational analytics could work for your organisation, or if you need help getting your data foundations in place first, get in touch. We've built these solutions, broken these solutions, and learned quite a lot in the process. Sometimes the most valuable insight is knowing which pitfalls to avoid.
This post is based on a recent Measurelab webinar on Conversational Analytics. Watch the full recording to see the tools in action, including the parts where they didn't quite work as expected.
FAQs
What are BigQuery "Verified Queries"?
Verified Queries (formerly known as "golden queries") are pre-validated SQL statements that act as templates for BigQuery Data Agents. Instead of the AI "guessing" how to join complex GA4 tables, it references these verified examples to ensure 100% logic accuracy for common business questions.
How do "Data Agents" improve NL-SQL accuracy?
BigQuery Data Agents provide a structured framework for AI by incorporating business glossaries from Dataplex and curated knowledge sources. This moves the AI away from relying solely on cryptic column names and toward using formal business definitions for metrics like "conversions" or "engaged sessions."
What is the role of the Model Context Protocol (MCP) in analytics?
The Model Context Protocol (MCP) is an open standard that allows LLMs to connect directly to data sources like BigQuery via a managed server. In 2026, this enables developers to build custom data tools that have a standardized, secure way to "read" database schemas and metadata without manual prompt engineering.
Need help with your data platform?
We build intelligence platforms on BigQuery, Dataform and Google Cloud — from setup to ongoing optimisation.