R For Analytics: A Beginner’s Guide, Part 3

IMPORTANT: THE PACKAGE HAS BEEN UPDATED BUT ADAM HASN’T HAD TIME TO UPDATE THIS YET! PROCEED AT YOUR PERIL!
Last time, we had a look at how we could use RGA to pull in account details and suchlike. It’s not essential, but I’d suggest you go back and read through it, as it might make some of what we do next a little easier – and, of course, if you haven’t done so already, read the first piece too and follow the instructions enumerated therein to allow you to do, well, any of this.
Data frames
Something about R that I should introduce you to is the idea of data frames. In maths terms, they’re lists of equal-length vectors, which is to say, basically, tables. If you run commands like the ones we looked out last week, the output will be printed to the console, but if you prepend it with something like
account_list <- [get_ accounts command]
you’ll get a data frame of all your accounts, which should be visible under the ‘data’ bit of the ‘environment’ window on the top-right of RStudio. If you click on it, you’ll be able to view it in the source viewer that occupies the upper-left quadrant of the screen.
Further, you can now output this stuff as, e.g. a .csv, which you’d do like so:
write.csv(account_list, file = “exported_account_list.csv”)
This may not be particularly useful for account lists, but it will be very useful if you want to get your data out of R. This exports the data to the working directory, by the way, which, unless you’ve specified otherwise will be the user root (on Mac, at least). This will come in especially useful as we look at the real issue here: how to get data out of GA.
get_ga
Now for the main course – actually getting data out of GA. This is actually in some pretty similar to using the spreadsheet plugin or query explorer, in that you have to outline several parameters and can then kick back and let the library do its work.
You’ll be building a query that looks something like this:
ga_data <- get_ga(profile.id = XXXXXXXXX, start.date = “dd/mm/yyyy”, end.date = “dd/mm/yyyy”, metrics = "ga:users,ga:sessions,ga:pageviews", dimensions = NULL, sort = NULL, filters = NULL, segment = NULL, start.index = NULL, max.results = NULL, token, verbose = getOption("rga.verbose", FALSE))
Some of those things you’ll want to fiddle with, some of them you won’t. You can leave null or just completely remove any of the things you’re not using (sort, filters, segment, start index etc) – they’re just included so you can see the kind of stuff you can do.
One thing that might be useful is paginating results, which allows you to run a bunch of queries for consecutive days and then stitch that back together, the code for which is:
dates <- seq(as.Date("2012-01-01"), as.Date("2012-02-01"), by = "days")
ga_data <- aggregate(. ~ keyword, FUN = sum, data = do.call(rbind, lapply(dates,function(d) {get_ga(profile.id = XXXXXXXX, start.date = d, end.date = d,metrics = "ga:sessions", dimensions = "ga:keyword”,filter = "ga:medium==organic;ga:keyword!=(not provided);ga:keyword!=(not set)”)})))
(obviously, substituting out whatever dates you want in the first line). This is great for pulling unsampled data, but if you’re not careful it can be a recipe for eating through a bunch of API queries really quickly (see below). It’s also worth noting that you do, in fact, have to provide a dimension in order to paginate the data like this – where it says “aggregate(. ~ keyword”, the keyword is the name of the dimension (sans ga: prefix).
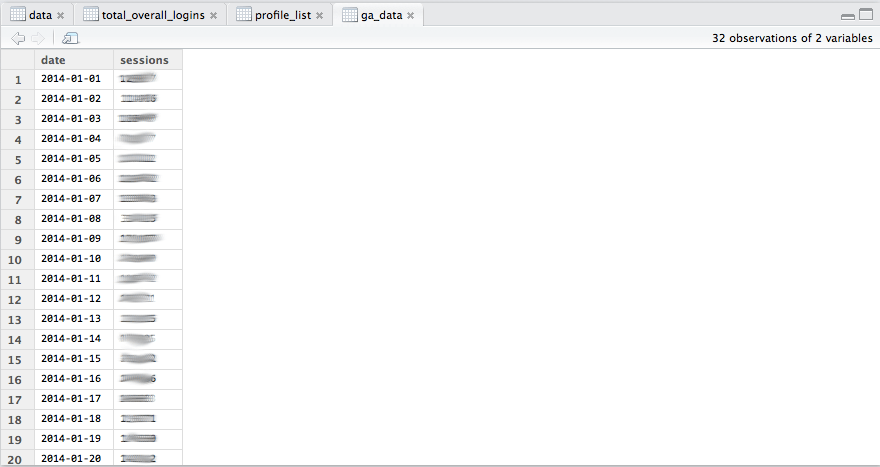
An example of a query, in this case using pagination, might look something like:
ga_data <- aggregate(. ~ date, FUN = sum, data = do.call(rbind, lapply(dates,function(d) {get_ga(profile.id = 12345678, start.date = d, end.date = d,metrics = "ga:sessions",dimensions = "ga:date")})))
and bring back results like:
It is also possibly, using the get_mcf and get_rt commands to get multi-channel funnel and realtime data. I’ve never found this necessary, but I’m mentioning it anyway for the sake of completeness. The commands can be found in the plugin itself (click on the name of the plugin in the plugin bit in the bottom-left).
What you can do is different to what you should do.
A further word of caution is necessary – one of the great benefits of R is its ability to pull large amounts of data, but you must also be vigilant. There are limits. It must also be remembered that R is not a panacea for data retrieval. Where it excels is its ability to pull large amounts of unfiltered data in a form that’s easy to manipulate or export as you wish, or taking many of those and stitching them all together. R is built for handling lots of data, it’s very robust. What it’s not so good at is pulling lots of things where there are many odd conditions applied, especially across a wide date range. Trying to do a big query like this with a multi-condition segment for a client recently, I realised one query by itself had chewed up 1000 queries of the 50,000 daily Analytics API query limit – but, more importantly, 1000 queries of the much more restrictive 10,000 daily view query limit. This is something to watch for. Don’t be overcautious or anything, just make sure you don’t use up your daily allowance if you think you’re going to need to pull data in the afternoon. Google documentation about the API limits is here.
What can you do with the data once you’ve got it?
You can export it into a .csv and do stuff with it in Excel or Google Sheets, but you might want to consider what you can do with all that data already in an incredibly powerful and versatile stats package. Next time on R For Analytics: A Beginner’s Guide, we consider what you can do with all that data already in an incredibly powerful and versatile stats package.

Subscribe to our newsletter:
Further reading
Backing up Universal Analytics data in BigQuery

How to deal with the GA4 Data API quota limitations in Looker Studio